

Slice-based Learning
Vincent S. Chen, Sen Wu, Zhenzhen Weng, Alexander Ratner, Christopher Ré
Sep 17, 2019
We introduce slice-based learning, a programming model for improving performance on application-critical data subsets, or slices. Specifically, we focus on 1) an intuitive interface for identifying such slices and 2) describe a modeling approach for improving slice performance that is agnostic to the underlying architecture. We view this work in the context of an emerging class of programming models 1 — slice-based learning is a paradigm that sits on top of traditional modeling approaches in machine learning systems.
In the wild… slice-based learning is deployed in production systems at Apple and was used to achieve state-of-the-art quality on the SuperGLUE benchmark, a suite of natural language understanding tasks.
NEWS: This work was presented at NeurIPS 2019 — please reference our full paper here!
# Overview
In machine learning applications, some model predictions are more important than others — a subset of our data might correspond to safety-critical settings in an autonomous driving task (e.g. detecting cyclists) or a critical but low-frequency healthcare demographic (e.g. younger patients with certain cancers). However, learning objectives are often configured to optimize for overall quality metrics, which tend to be coarse-grained. In addition to overall performance, we’d like to monitor and improve fine-grained model performance on application-critical subsets, which we call slices.
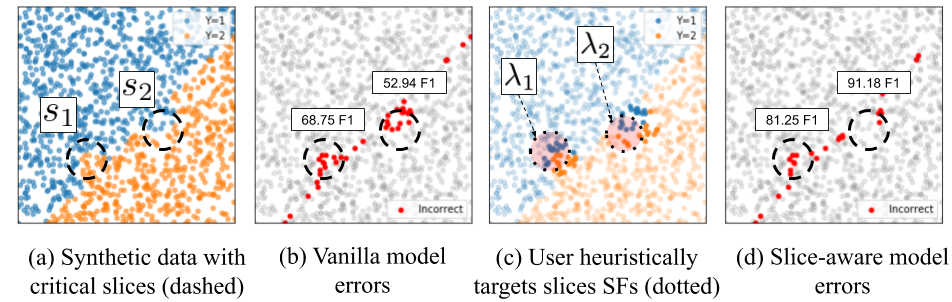
We discuss two high-level challenges for addressing slice performance in practical applications:
- Specifying slices for fine-grained performance monitoring
- Improving model performance on critical data slices
# Challenge: Specifying slices for fine-grained performance monitoring
In machine learning deployments, monitoring metrics on fine-grained data slices is an important workflow — these metrics are often tied to product goals (e.g. serving users in a geographic region) or safety goals (e.g. night-time autonomous driving). Furthermore, slices are dynamic, as shifting data distributions or application goals will elicit different monitoring needs. As a result, an effective ML pipeline needs to support iterative specification and evaluation of such dynamic slices.
In practice, however, slices are difficult to specify precisely. Domain experts or practitioners might have intuition about the nature of a slice (often, as a result of an error analysis), but translating this to a precise, machine-understandable description can be challenging, e.g. “the slice of data that contains a yellow traffic light at dusk”. As a result, we turn to heuristic methods to define slices.
# Heuristically-defined slices as weak supervision
We leverage a key programming abstraction, the slicing function (SF), as an efficient and intuitive interface for specifying slices.

An SF can be viewed as a simple black-box function that accepts as input a data point and outputs a binary indicator specifying whether the data point belongs to a particular slice. SFs can be expressed in a number of forms, from pattern-based rules to wrappers around off-the-shelf classifiers. Specifically, SFs may be heuristically or noisily defined; they can be seen as a form of weak supervision 2 for programmatically (and noisily) indicating data subsets of interest.
*Note: For those familiar with the Snorkel paradigm, you may notice that slicing functions share syntax with labeling functions! Key differences: 1) LFs output class labels and SFs output a binary indicator, and 2) A single SF maps to a single slice, whereas multiple labeling functions can often specify the same label.
# From non-servable slicing functions (SFs) to servable models
We note that SFs may incorporate specific metadata or pretrained models — these are multi-modal sources of supervision (e.g. text reports for MRI scans) or memory-inefficient, pre-trained classifiers (off-the-shelf classifier). We call these resources non-servable 3 — they are available during offline training, but are not feasibly accessible when the model is deployed. As a result, a key assumption of our approach is that SF outputs are not available during inference — to represent those outputs, our approach will need to learn weights that can be transferred to a servable model.
# SFs for monitoring dynamic datasets
Ultimately, SFs serve as an effective interface for indicating important subsets for monitoring — they are intuitive for practitioners to specify and flexible to target dynamic data distributions. Given this abstraction, we now discuss our modeling approach for improving slice performance, which is robust to noisy SF outputs.
# Challenge: Improving model performance on critical data slices
Now that we have a method for specifying slices, we’d like to improve model performance on those slices. We describe baseline modeling approaches and their limitations before describing our attention-based approach.
# Improving model performance with representation learning
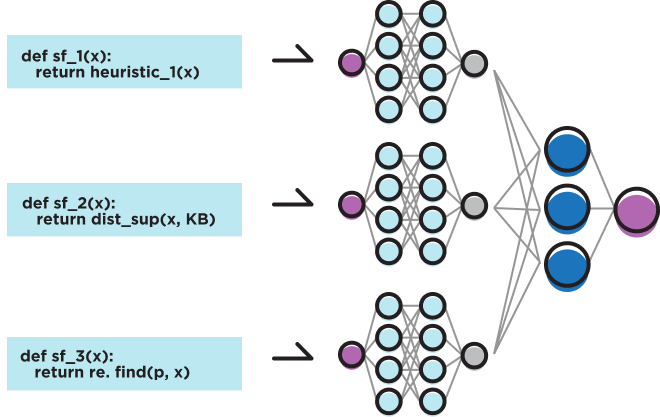
In one intuitive approach, we create a separate expert model for each slice — each model is trained only on examples belonging to the slice. To produce a single prediction at inference, we train a mixture of experts (MoE) — a gating network that decides how to combine expert predictions intelligently. However, due to the growing size of machine learning models, this approach could require training and deploying hundreds of large models — one for each slice. Consequently, the run-time performance of this approach quickly becomes untenable at scale.
# Multi-task learning for parameter-efficient representations
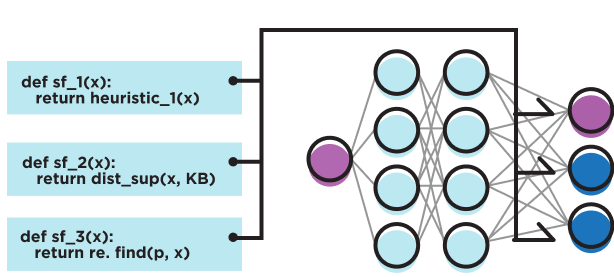
We’d like an approach that is more parameter efficient. We note that each expert performs the same task (e.g. image classification), only on different subsets of the data. As a result, we can likely share parameters!
In the style of multi-task learning, 4 we might instead formulate slice experts as slice-specific task heads learned via hard parameter sharing.4 These slice tasks would be learned on top of a shared neural network architecture, which we call the backbone. Using the backbone as a shared representation, we significantly reduce the number of parameters, compared to MoE. For reference, adding a single slice to a BERT-large model (with 340M parameters) would result in a roughly 0.6% increase in parameters, whereas for MoE, a single slice would cost a 100% increase in parameter count!
Despite the parameter-efficient representation, the hard parameter sharing approach relies solely on representation bias 5 from different slice tasks to improve the shared representation in the backbone architecture. As we increase the number of slices, we might end up worsening performance on existing slices or overall. Practitioners are consequently tasked with manually tuning weights per task head (e.g. via loss multipliers) — this process becomes inefficient at scale!
# Technical challenges of slice-based learning
While the aforementioned approaches might work in settings with a limited number of slices, they fail to scale with realistic, practitioner workflows where dozens, or even hundreds, of slices might be required for monitoring purposes. We leverage intuition from these approaches to outline and address the following key challenges:
- Coping with noise: SFs are specified as weak supervision; the model will need to be robust to noisy SF outputs.
- Scalability: As we add more slices to the model, we must maintain a parameter-efficient representation (as opposed to making multiple copies of large models).
- Stable improvement of the model: As the number of slices scale, we don’t want to worsen performance on existing slices or overall — there’s no free lunch!
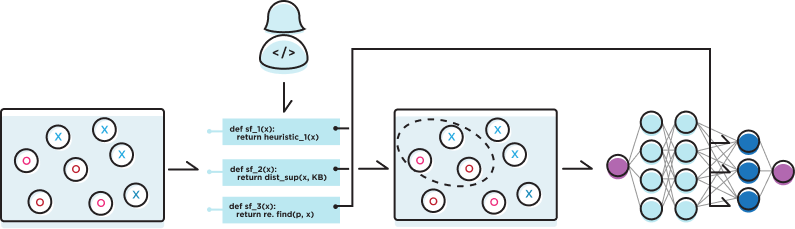
# Slice Residual Attention Modules (SRAMs)
With these challenges in mind, we highlight the high-level intuition for our approach: we’d like to train a standard prediction model, which we call the base task. For each slice, we initialize weights branching off from shared parameters in the backbone architecture—these weights serve as an “expert representation”, trained based on the corresponding SF outputs. Using an attention mechanism we combine these expert representations into a slice-aware representation, from which we can make a final prediction!
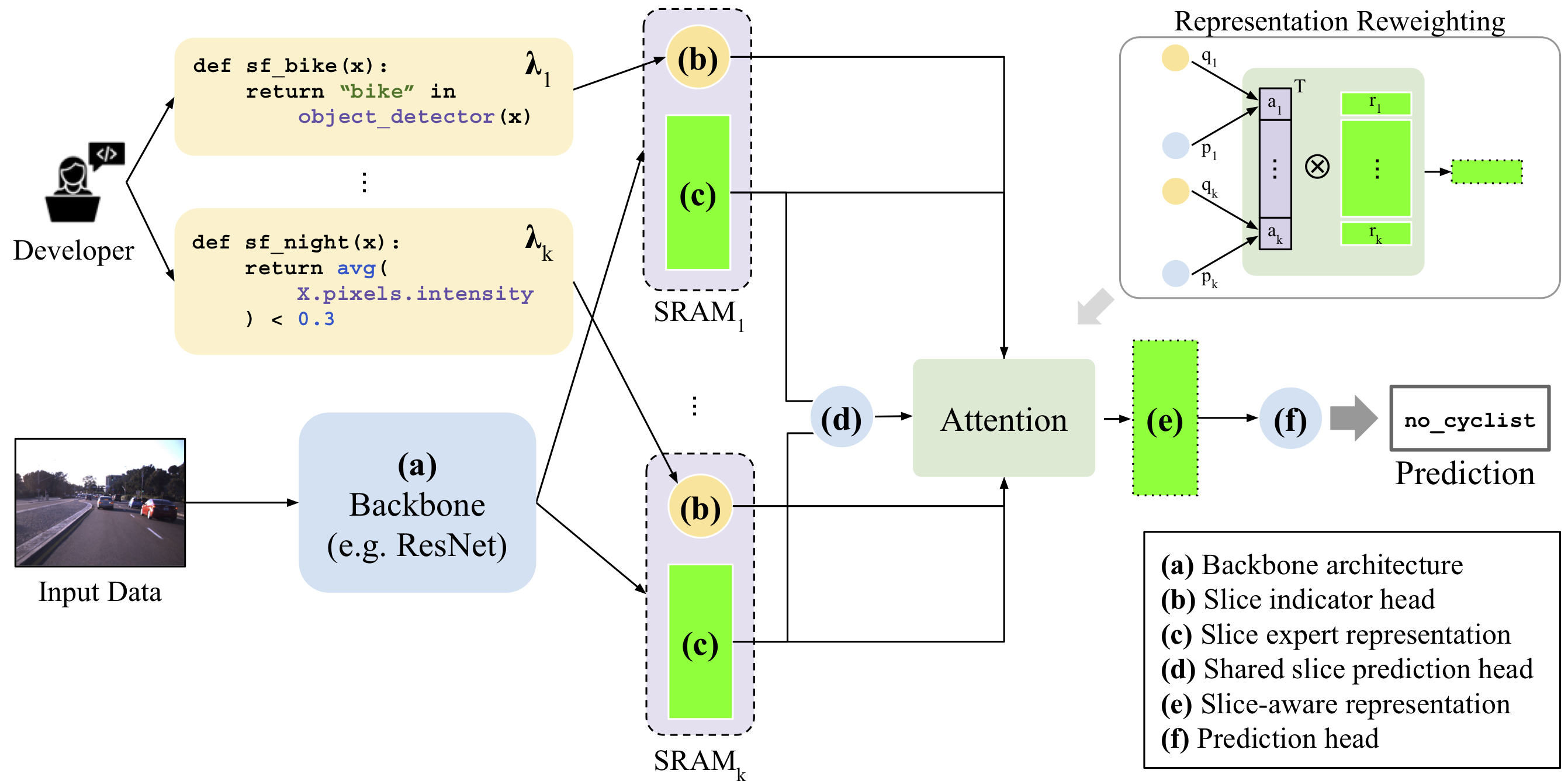
Specifically, we introduce the notion of the slice residual attention module, which models the residual between the base task and slice representations. It consists of the following components:
- (a) Backbone: Any neural network architecture (e.g. the latest transformer for text, CNN for images) that will be used to map the input data to some shared representation in latent space.
- (b) Slice indicator heads: For each slice, we learn an “indicator task” from the backbone — this task head’s goal is to learn the output of the corresponding SF.
- (c) Slice-specific representations: For each slice, we learn “expert features”, which we call a slice-specific representation, which branches off from the backbone representation. For each representation, we backpropagate loss only for examples belonging to the slice.
- (d) Shared slice prediction head: A shared slice prediction head is used to train the slice-specific representations. We use a shared prediction head to ensure that expert heads’ outputs are combined in a consistent manner.
- (e) Slice-aware representation: We use the element-wise product of the slice indicator output and prediction head confidence as attention weights to reweight the slice-specific representations into a slice-aware representation. This attention mechanism is robust to noisy SFs: if the slice indicators or prediction tasks make un-confident predictions, it will downweight the corresponding representation.
- (f) Prediction head: Using the slice-aware representation as a set of features, a final prediction head is used to output model predictions on the base task.
For further experiments and ablations about the architecture, please see our technical paper.
# Takeaways
We present an intuitive programming abstraction, the slicing function, for practitioners to monitor fine-grained performance on application-critical data subsets. We then describe a parameter-efficient modeling approach that leverages slicing functions to improve slice performance using any backbone architecture.
# Future Work
We are excited about future work that builds on effective interfaces and modeling approaches for Slice-based learning. In the broader context of weak supervision literature, we introduce programmatic model supervision, where the slicing function is a viable interface to improving model performance.
# Resources
- Tutorial: A tutorial for slice-based learning using a spam dataset
- Code: Our open-source implementation in the Snorkel
- Paper: Our full paper (to appear in NeurIPS 2019), for more details!
- Production Deployment: How slice-based learning is used in Apple’s production machine learning system, Overton
- State-of-the-art on SuperGLUE: A tutorial on how slices were used to achieve state-of-the-art scores on the SuperGLUE benchmark
# Acknowledgements
The authors would like to thank Braden Hancock, Feng Niu, and Charles Srisuwananukorn for many helpful discussions, tests, and collaborations throughout the development of slice-based learning!
# References
-
A. Karpathy. 2017. Software 2.0.. ↩
-
Alex Ratner, Stephen Bach, Paroma Varma, Chris Ré. 2017. An Overview of Weak Supervision. ↩
-
Alex Ratner, Cassandra Xia. 2019. Harnessing Organizational Knowledge for Machine Learning. ↩
-
Rich Caruana. 1997. Multitask learning. ↩ ↩2
-
Sebastian Ruder. 2017. An Overview of Multi-Task Learning in Deep Neural Networks. ↩